

As event sourced micro-services become one of the most popular architectures to build distributed, data-consistent, large scale systems, many companies find themselves facing the ultimate equation of System Efficiency vs Cost. Being ready for large scale data inflow at any given time while keeping the compute cost at its lowest is a challenge we have faced at Trax as well. In this blog we will showcase our dedicated solution using some of the basic APIs given by all cloud providers. This innovative approach has helped us minimize the delays in the system and save ~65% of the compute cost.
This state of the art innovation was featured by AWS in an episode of This is My Architecture.

At Trax, we digitize the physical world of retail using Computer Vision. The transformation of individual shelf images into data and insights about retail store conditions is made possible with the ‘Trax Factory’. Built using asynchronous event-driven architecture, the Trax Factory is a cluster of microservices in which the completion of one service triggers the activation of another service.
The Trax Computer Vision Factory Architecture
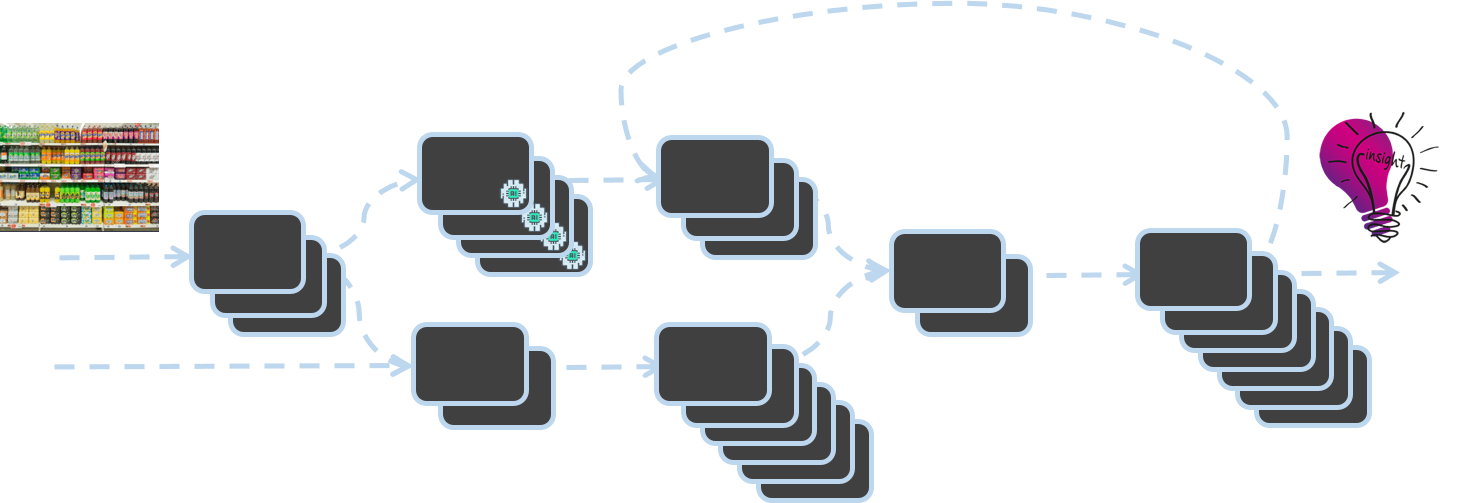
This blog discusses the need for a robust, scalable infrastructure to support the Trax Factory and introduces innovative solutions developed by Trax engineers to add and remove capacity based on demand. Learn how Trax built an EC2 Auto Scaling Groups-based message processing system for SNS/SQS that can scale every second. Our solution goes beyond classic 5-minute queue depth scanning with CloudWatch, allowing us to reduce downtime, avoid data losses and improve overall service levels.
The Need for Scale
In the early 90s, Electronic Arts published a racing video game called Need for Speed that tasked players to complete various types of races while evading law enforcement in police pursuits.
This was also around the same time that computers used by various companies were becoming more diffused, and scientists and technologists explored ways to make large-scale computing power available to more users through time-sharing. Thus began the era of cloud computing, and with it, the enduring challenge of infrastructure optimization. In this game of Need for Scale, infrastructure teams add and remove system capacity while adhering to laws put in place by COOs, CFOs and CTOs. Trax engineers, like their peers in other cloud-based technology companies, needed to optimize scale while improving client service levels, reducing costs and retaining IT system simplicity.
The scaling challenge at Trax
Trax has the most advanced Computer Vision platform for retail in the industry, with a sophisticated backend system that processes millions of shelf images each month.
A new image entering the system is one of the main events handled by the Trax backend. This event triggers a micro service that recognizes products in the image using advanced deep learning algorithms. This process is asynchronous in that no other micro service that is waiting for a response from this image recognition service. Its task ends when it publishes an event once it completes the processing activity and provides the results. Various micro services in the Trax Factory are working in this manner, constantly carrying out numerous activities like stitching, geometry and so much more, each involving different degrees of computational complexity.
Transforming millions of images across multiple projects around the globe into targeted, specific insights for clients takes up a lot of computing horsepower while putting strain on IT budgets.
Typically, decisions on whether to scale out or scale in capacity (add or reduce machines respectively) are made based on basic queue depth metrics provided by cloud providers – for e.g. how many messages are there in the queue.
There are two significant barriers for this scaling policy:
In a complex system like Trax where images enter the factory in varying volumes, and the load on each service is different than the other, queue depth information becomes stale over 5-minute intervals. This presents the risk of not only detecting the required compute power very late and harming SLAs, but also incurring additional costs while making scale adjustments.
Illustration of Scaling Monitor using out-of-the-box capacity metrics
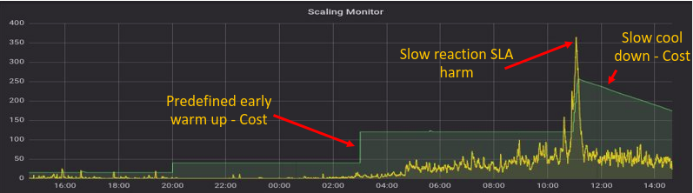
As the chart indicates, relying on out-of-the-box metrics to monitor capacity utilization every 5 minutes results in incurring costs on machines that are not in use, as well as harming service levels by running inadequate machines (e.g. between 10.00 and 12.00 on the chart).
Going beyond queue depth as a scale metric
Queue depth has been and will continue to be a key influencing factor in scaling decisions within event-based systems. But relying solely on queue depth as a scale metric creates a reactive approach to infrastructure optimization.
When there’s a message waiting in a queue, it takes up precious compute time that we’d rather spend on a message that’s being processed by a service. So, it’s ideal to have some amount of spare compute power at any given time. These spare systems wait for new messages to arrive into the queue so that they can be immediate processed with no delays. Naturally, this proactive approach is better than having to add machines when messages are already in the queue and scale in when the queue is already empty. The need for spare power reveals an important insight – queue depth doesn’t tell the whole story.
So, the correct equation for scaling should in fact be:
Demand = Messages in queue + messages in process + spare machines
The case for more frequent capacity and load measurement
As we’ve established in the previous sections, relying on scaling metrics only once in 5 minutes is not only costly but also hampers service levels and customer satisfaction. To overcome this, we developed a service that measures queue depth and messages in process every second via API. Comparing the old sampling method with the new, the improvements were very clear. In the illustration below, the demand (yellow line) never exceeds the supply (green line).
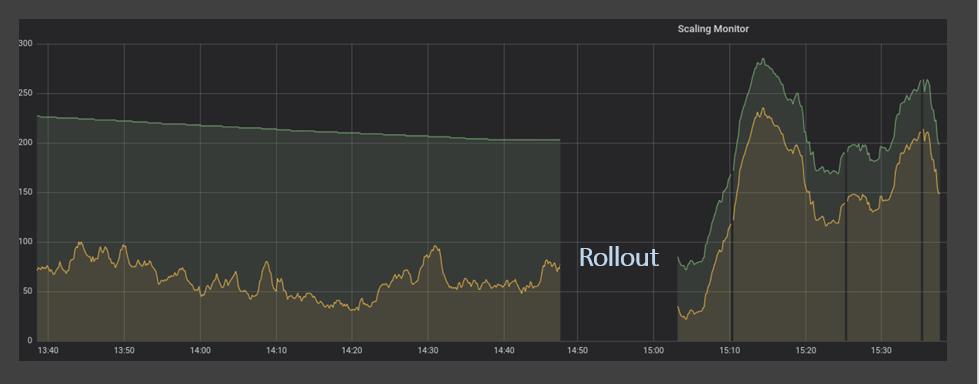
Notice that when the demand spikes up sharply, the supply reacts very fast effectively protecting our customers from unpleasant delays in service.
In addition, this method helps keep our spare computer power in tight alignment with demand rather than spending it on idle instances that are waiting for new messages.
Scaling in and out with care
Aggressive scaling done incorrectly has one clear and present danger – the possibility of scaling in machines that are still processing information. In the Trax factory for example, geometry-based algorithms typically take up more processing time compared to other services. Taking away computing power from this service too soon results in the message being returned to the queue. As a consequence, in addition of indicating the natural inflow into the system, the demand reports include messages that are returning to the queue for the second time, and maybe return for a third or fourth time. This load can increase drastically over time and impact both costs and service levels.
To prevent this from happening, we implemented a mechanism wherein services which raise a flag indicating they are still processing messages are ‘locked out’. This prevents such instances from being subjected to scaling decisions. Most cloud providers offer features that ‘protect’ instances selectively. Once the service completes message processing, it takes the flag down and returns to the pool of computing resources participating in the scaling game. This capability ensures that only idle machines are scaled in.

In the graph above, we see demand and supply in harmony. But notice something we didn’t see before. There’s a new red line that always stays close to the X-axis. This line represents the delay in our system. In effect, this is the amount of time for which the oldest message resides in the queue before being processed. The fact that supply-demand lines are functioning the way they should combined with the delay being close to zero at most times means that service levels are unharmed.
Robust fallback
As Werner Vogels, CTO of Amazon says, “everything fails all the time”. We’ve introduced a major technological change and developed a service that measures queue depth and messages in process and performs a scale operation on our system. This service failing effectively means that we’ll lose all scaling ability – the stuff that CTO’s nightmares are made of. To prevent this, a disaster recovery plan is put in place. The original mechanism of querying queue depth every 5 minutes is still in place and the two systems work in parallel. This way, if one of them crashes, service levels are not very adversely affected.
The takeaways
Here’s a depiction of our fully functional solution working on a typical day in the middle of the week:
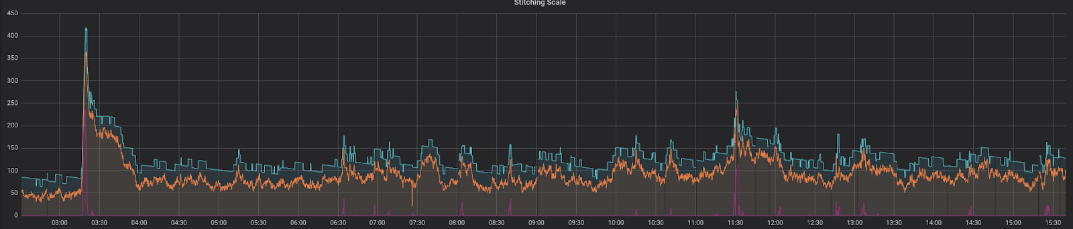
This shows a perfect correlation between the expected (orange line) and the actual machines (blue line), with sufficient amount of spare compute power. The amount of time for which the oldest message resides in the queue before being processed (red line) is consistently low, spiking only for very short periods of time.
To summarize, building a scaling mechanism for asynchronous event-driven systems that Trax has four foundational pillars:
Success is defined by how happy the law enforcement officers for the Need for Scale game – the CFO, COO and CTO – are with the solution. The outcome of this innovation is benefiting everyone:
A session on this topic was also delivered by Michael Feinstein at Reversim 2018. Click the play button to watch the full session.










