
À medida que os micro-serviços de origem de eventos se tornam uma das arquitecturas mais populares para construir sistemas distribuídos, consistentes com os dados e de grande escala, muitas empresas dão por si a enfrentar a equação final de Eficiência do Sistema vs Custo. Estar pronto para o influxo de dados em grande escala a qualquer momento, mantendo o custo de computação no seu nível mais baixo, é um desafio que também enfrentámos na Trax. Neste blogue, vamos apresentar a nossa solução dedicada utilizando algumas das APIs básicas fornecidas por todos os fornecedores de serviços na nuvem. Esta abordagem inovadora ajudou-nos a minimizar os atrasos no sistema e a poupar ~65% do custo de computação.
Esta inovação de última geração foi apresentada pela AWS num episódio de This is My Architecture.

Na Trax, digitalizamos o mundo físico do retalho utilizando a Visão por Computador. A transformação de imagens de prateleiras individuais em dados e informações sobre as condições das lojas de retalho é possível com a "Trax Factory". Construída utilizando uma arquitetura assíncrona orientada para eventos, a Trax Factory é um conjunto de microsserviços em que a conclusão de um serviço desencadeia a ativação de outro serviço.
A arquitetura da fábrica de visão computacional Trax
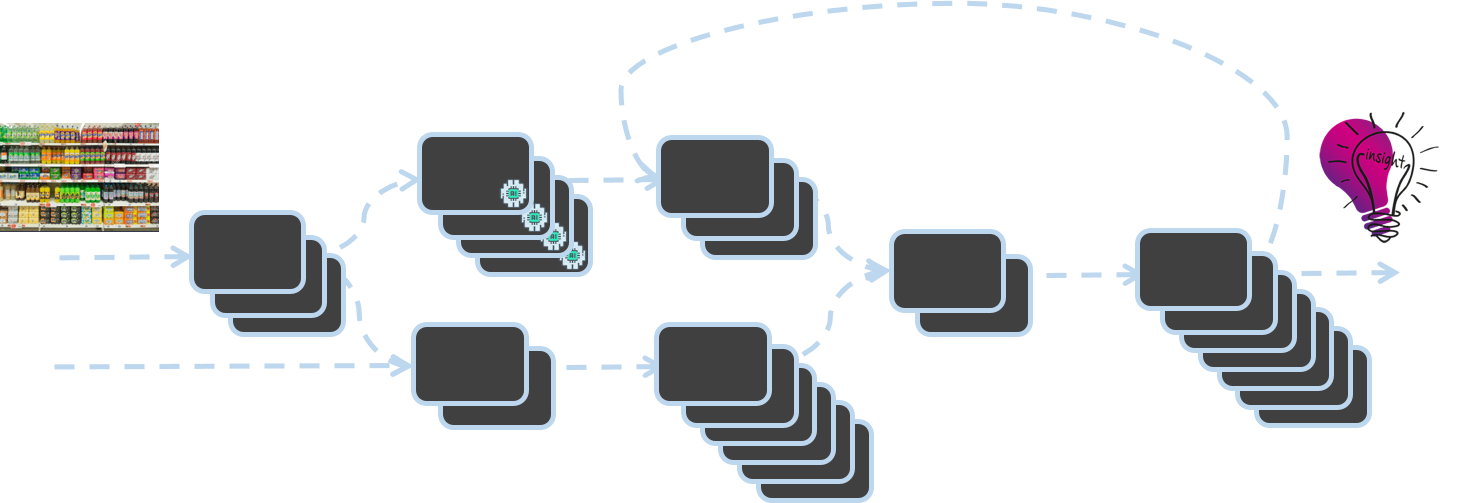
Este blogue discute a necessidade de uma infraestrutura robusta e escalável para suportar a Trax Factory e apresenta soluções inovadoras desenvolvidas pelos engenheiros da Trax para adicionar e remover capacidade com base na procura. Saiba como a Trax criou um sistema de processamento de mensagens baseado em grupos de dimensionamento automático EC2 para SNS/SQS que pode ser dimensionado a cada segundo. Nossa solução vai além da verificação clássica de profundidade de fila de 5 minutos com o CloudWatch, o que nos permite reduzir o tempo de inatividade, evitar perdas de dados e melhorar os níveis gerais de serviço.
A necessidade de escala
No início dos anos 90, a Electronic Arts publicou um videojogo de corridas chamado Need for Speed, que obrigava os jogadores a completar vários tipos de corridas enquanto fugiam às forças da ordem em perseguições policiais.
Esta foi também a mesma altura em que os computadores utilizados por várias empresas se tornaram mais difusos e os cientistas e tecnólogos exploraram formas de disponibilizar o poder de computação em grande escala a mais utilizadores através da partilha de tempo. Assim começou a era da computação em nuvem e, com ela, o desafio permanente da otimização da infraestrutura. Neste jogo de Necessidade de Escala, as equipas de infraestrutura adicionam e removem capacidade do sistema, respeitando as leis estabelecidas pelos COOs, CFOs e CTOs. Os engenheiros da Trax, tal como os seus pares noutras empresas de tecnologia baseadas na nuvem, precisavam de otimizar a escala, melhorando simultaneamente os níveis de serviço ao cliente, reduzindo os custos e mantendo a simplicidade do sistema de TI.
O desafio do escalonamento no Trax
A Trax tem a mais avançada plataforma de Visão por Computador para o retalho na indústria, com um sofisticado sistema de backend que processa milhões de imagens de prateleiras todos os meses.
Uma nova imagem que entra no sistema é um dos principais eventos tratados pelo backend do Trax. Este evento acciona um micro serviço que reconhece os produtos na imagem utilizando algoritmos avançados de aprendizagem profunda. Este processo é assíncrono, na medida em que nenhum outro micro-serviço está à espera de uma resposta deste serviço de reconhecimento de imagens. A sua tarefa termina quando publica um evento depois de concluir a atividade de processamento e fornecer os resultados. Vários microsserviços na Trax Factory estão a trabalhar desta forma, realizando constantemente inúmeras actividades como a costura, a geometria e muito mais, cada uma envolvendo diferentes graus de complexidade computacional.
Transformar milhões de imagens de vários projectos em todo o mundo em informações específicas e orientadas para os clientes exige muita capacidade de computação e sobrecarrega os orçamentos de TI.
Normalmente, as decisões sobre o aumento ou a redução da capacidade (adicionar ou reduzir máquinas, respetivamente) são tomadas com base em métricas básicas de profundidade da fila fornecidas pelos fornecedores de serviços de computação em nuvem - por exemplo, quantas mensagens existem na fila.
Existem dois obstáculos significativos a esta política de expansão:
Num sistema complexo como o Trax, em que as imagens entram na fábrica em volumes variáveis e a carga em cada serviço é diferente da outra, as informações sobre a profundidade da fila tornam-se obsoletas em intervalos de 5 minutos. Isto apresenta o risco não só de detetar a potência de computação necessária muito tarde e prejudicar os SLAs, mas também de incorrer em custos adicionais ao fazer ajustes de escala.
Ilustração do Scaling Monitor usando métricas de capacidade prontas para uso
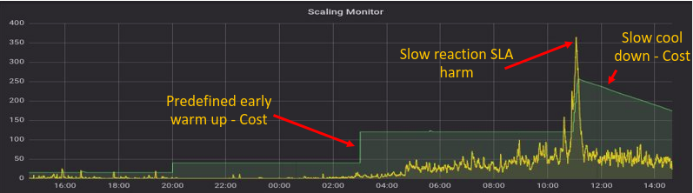
Tal como o gráfico indica, confiar em métricas prontas a utilizar para monitorizar a utilização da capacidade a cada 5 minutos resulta em custos em máquinas que não estão a ser utilizadas, bem como em prejuízos para os níveis de serviço ao fazer funcionar máquinas inadequadas (por exemplo, entre as 10h00 e as 12h00 no gráfico).
Ir além da profundidade da fila como métrica de escala
A profundidade da fila tem sido e continuará a ser um fator de influência fundamental nas decisões de escalonamento em sistemas baseados em eventos. Mas confiar apenas na profundidade da fila como uma métrica de escala cria uma abordagem reativa para a otimização da infraestrutura.
Quando há uma mensagem à espera numa fila, esta ocupa um tempo de computação precioso que preferíamos gastar numa mensagem que está a ser processada por um serviço. Portanto, é ideal ter alguma quantidade de poder computacional sobressalente a qualquer momento. Estes sistemas de reserva aguardam que novas mensagens cheguem à fila de espera para que possam ser imediatamente processadas sem atrasos. Naturalmente, esta abordagem proactiva é melhor do que ter de adicionar máquinas quando as mensagens já estão na fila e aumentar a escala quando a fila já está vazia. A necessidade de energia de reserva revela uma importante perceção - a profundidade da fila não conta toda a história.
Assim, a equação correta para o escalonamento deve ser, de facto, a seguinte:
Procura = Mensagens em fila de espera + mensagens em processamento + máquinas disponíveis
A necessidade de uma medição mais frequente da capacidade e da carga
Como estabelecemos nas secções anteriores, confiar em métricas de escala apenas uma vez em 5 minutos não só é dispendioso como também prejudica os níveis de serviço e a satisfação do cliente. Para ultrapassar este problema, desenvolvemos um serviço que mede a profundidade da fila e as mensagens em processamento a cada segundo através da API. Comparando o antigo método de amostragem com o novo, as melhorias foram muito claras. Na ilustração abaixo, a procura (linha amarela) nunca excede a oferta (linha verde).
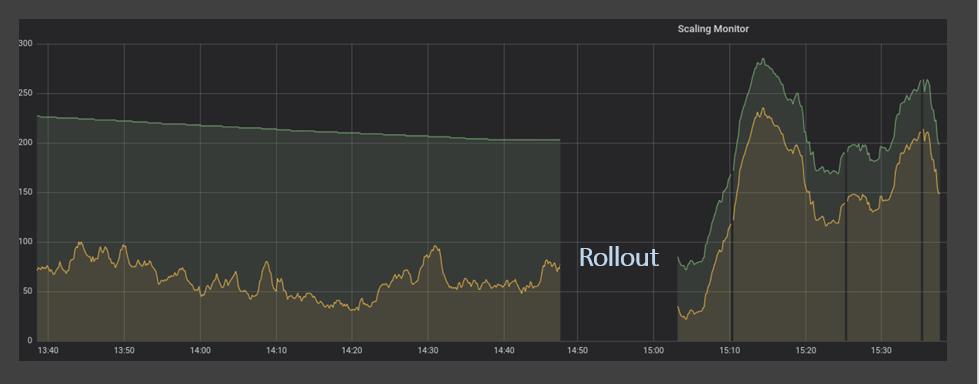
Repare-se que, quando a procura aumenta acentuadamente, a oferta reage muito rapidamente, protegendo eficazmente os nossos clientes de atrasos desagradáveis no serviço.
Além disso, este método ajuda a manter a potência de reserva dos nossos computadores em estreita sintonia com a procura, em vez de a gastar em instâncias inactivas que estão à espera de novas mensagens.
Escalar para dentro e para fora com cuidado
O escalonamento agressivo feito de forma incorrecta tem um perigo claro e presente - a possibilidade de escalonamento em máquinas que ainda estão a processar informação. No Trax Factory, por exemplo, os algoritmos baseados em geometria ocupam normalmente mais tempo de processamento do que outros serviços. Retirar poder de computação a este serviço demasiado cedo faz com que a mensagem seja devolvida à fila de espera. Consequentemente, para além de indicar o afluxo natural ao sistema, os relatórios de procura incluem mensagens que regressam à fila pela segunda vez, e talvez pela terceira ou quarta vez. Esta carga pode aumentar drasticamente ao longo do tempo e afetar tanto os custos como os níveis de serviço.
Para evitar que isto aconteça, implementámos um mecanismo em que os serviços que levantam uma bandeira indicando que ainda estão a processar mensagens são "bloqueados". Isso impede que essas instâncias sejam submetidas a decisões de escalonamento. A maioria dos provedores de nuvem oferece recursos que "protegem" as instâncias de forma seletiva. Uma vez concluído o processamento de mensagens, o serviço retira a bandeira e regressa ao conjunto de recursos informáticos que participam no jogo de escalonamento. Essa capacidade garante que apenas máquinas ociosas sejam escaladas.

No gráfico acima, vemos a procura e a oferta em harmonia. Mas repare numa coisa que não vimos antes. Há uma nova linha vermelha que fica sempre perto do eixo X. Esta linha representa o atraso no nosso sistema. De facto, esta é a quantidade de tempo que a mensagem mais antiga permanece na fila antes de ser processada. O facto de as linhas de oferta e procura estarem a funcionar como deveriam, combinado com o facto de o atraso ser próximo de zero na maioria das vezes, significa que os níveis de serviço não são afectados.
Recuo robusto
Como diz Werner Vogels, CTO da Amazon, "tudo falha a toda a hora". Introduzimos uma grande mudança tecnológica e desenvolvemos um serviço que mede a profundidade da fila e as mensagens em processamento e executa uma operação de escala no nosso sistema. A falha deste serviço significa efetivamente que perderemos toda a capacidade de escalonamento - aquilo de que são feitos os pesadelos dos CTOs. Para evitar isso, é implementado um plano de recuperação de desastres. O mecanismo original de consultar a profundidade da fila a cada 5 minutos ainda está em vigor e os dois sistemas funcionam em paralelo. Desta forma, se um deles falhar, os níveis de serviço não são afectados de forma muito negativa.
As conclusões
Aqui está uma representação da nossa solução totalmente funcional a funcionar num dia típico a meio da semana:
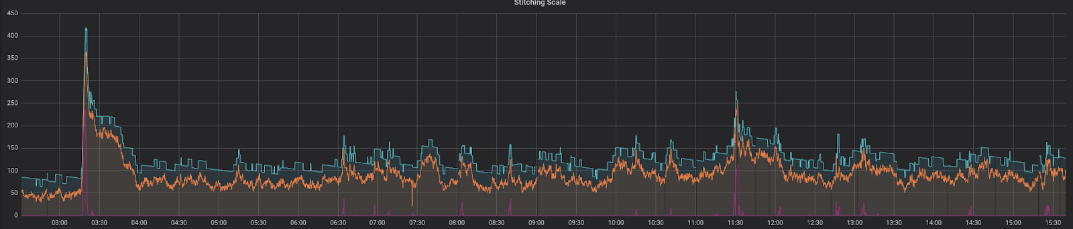
Este facto mostra uma correlação perfeita entre as máquinas esperadas (linha laranja) e as máquinas reais (linha azul), com uma quantidade suficiente de potência computacional disponível. O período de tempo durante o qual a mensagem mais antiga permanece na fila antes de ser processada (linha vermelha) é consistentemente baixo, registando picos apenas em períodos de tempo muito curtos.
Para resumir, a construção de um mecanismo de escalonamento para sistemas assíncronos orientados a eventos que o Trax tem quatro pilares fundamentais:
O sucesso é definido pelo grau de satisfação dos responsáveis pela aplicação da lei no jogo Need for Scale - o diretor financeiro, o diretor de operações e o diretor técnico - com a solução. O resultado desta inovação está a beneficiar toda a gente:
Uma sessão sobre este tema foi também apresentada por Michael Feinstein no Reversim 2018. Clique no botão de reprodução para ver a sessão completa.










