
A medida que los microservicios basados en eventos se consolidan como una de las arquitecturas más populares para construir sistemas distribuidos, con consistencia de datos y a gran escala, muchas empresas se enfrentan a la ecuación definitiva de Eficiencia del Sistema vs. Costo. Estar preparados para un flujo masivo de datos en cualquier momento, manteniendo los costos de cómputo al mínimo, es un desafío que también hemos enfrentado en Trax. En este blog, presentaremos nuestra solución dedicada, que utiliza algunas de las API básicas proporcionadas por todos los proveedores de la nube. Este enfoque innovador nos ha permitido minimizar los retrasos en el sistema y ahorrar aproximadamente un 65% del costo de cómputo.
Esta innovación de vanguardia fue destacada por AWS en un episodio de 'This is My Architecture'.

En Trax, digitalizamos el mundo físico del retail mediante Visión por Computadora. La transformación de imágenes individuales de estantes en datos e información sobre las condiciones de las tiendas minoristas es posible gracias a la 'Trax Factory'. Construida con una arquitectura asíncrona basada en eventos, la Trax Factory es un clúster de microservicios en el que la finalización de un servicio desencadena la activación de otro.
La Arquitectura de la Fábrica de Visión por Computadora de Trax
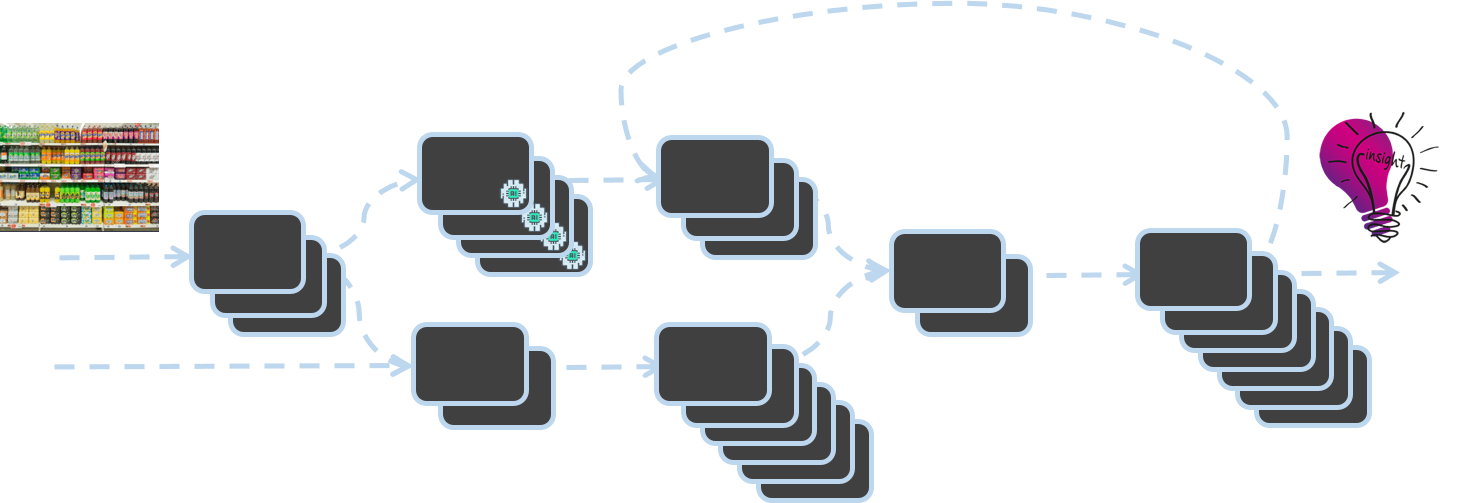
Este blog aborda la necesidad de una infraestructura robusta y escalable para soportar la Trax Factory y presenta soluciones innovadoras desarrolladas por los ingenieros de Trax para añadir y eliminar capacidad según la demanda. Descubra cómo Trax construyó un sistema de procesamiento de mensajes basado en EC2 Auto Scaling Groups para SNS/SQS que puede escalar cada segundo. Nuestra solución va más allá del clásico escaneo de profundidad de cola de 5 minutos con CloudWatch, lo que nos permite reducir el tiempo de inactividad, evitar la pérdida de datos y mejorar los niveles de servicio generales.
La Necesidad de Escala
A principios de los 90, Electronic Arts publicó un videojuego de carreras llamado Need for Speed que desafiaba a los jugadores a completar diversos tipos de carreras mientras evadían a las fuerzas del orden en persecuciones policiales.
Fue también por esta época cuando los ordenadores utilizados por diversas empresas se estaban difundiendo más, y científicos y tecnólogos exploraron formas de poner a disposición de más usuarios la capacidad de cómputo a gran escala mediante el tiempo compartido. Así comenzó la era de la computación en la nube y, con ella, el desafío constante de la optimización de la infraestructura. En este juego de 'La Necesidad de Escala', los equipos de infraestructura añaden y eliminan capacidad del sistema, adhiriéndose a las directrices establecidas por los COOs, CFOs y CTOs. Los ingenieros de Trax, al igual que sus homólogos en otras empresas de tecnología basadas en la nube, necesitaban optimizar la escala mientras mejoraban los niveles de servicio al cliente, reducían los costos y mantenían la simplicidad del sistema de TI.
El desafío de la escalabilidad en Trax
Trax cuenta con la plataforma de Visión por Computadora más avanzada para el sector minorista, con un sofisticado sistema de backend que procesa millones de imágenes de estantes cada mes.
La entrada de una nueva imagen en el sistema es uno de los eventos principales gestionados por el backend de Trax. Este evento desencadena un microservicio que reconoce productos en la imagen utilizando algoritmos avanzados de aprendizaje profundo. Este proceso es asíncrono, lo que significa que ningún otro microservicio espera una respuesta de este servicio de reconocimiento de imágenes. Su tarea finaliza cuando publica un evento una vez que completa la actividad de procesamiento y proporciona los resultados. Varios microservicios en la Trax Factory operan de esta manera, realizando constantemente numerosas actividades como la unión de imágenes, geometría y mucho más, cada una implicando diferentes grados de complejidad computacional.
Transformar millones de imágenes de múltiples proyectos en todo el mundo en información específica y dirigida para los clientes requiere una gran capacidad de procesamiento computacional, al tiempo que ejerce presión sobre los presupuestos de TI.
Normalmente, las decisiones sobre si escalar horizontalmente (scale out) o verticalmente (scale in) la capacidad (añadir o reducir máquinas, respectivamente) se toman basándose en métricas básicas de profundidad de cola proporcionadas por los proveedores de la nube —por ejemplo, cuántos mensajes hay en la cola.
Existen dos barreras significativas para esta política de escalado:
En un sistema complejo como Trax, donde las imágenes entran en la fábrica en volúmenes variables y la carga de cada servicio difiere, la información de la profundidad de la cola se vuelve obsoleta en intervalos de 5 minutos. Esto presenta el riesgo no solo de detectar la potencia de cómputo requerida muy tarde y perjudicar los SLA, sino también de incurrir en costos adicionales al realizar ajustes de escala.
Ilustración del Monitor de Escalado utilizando métricas de capacidad predeterminadas
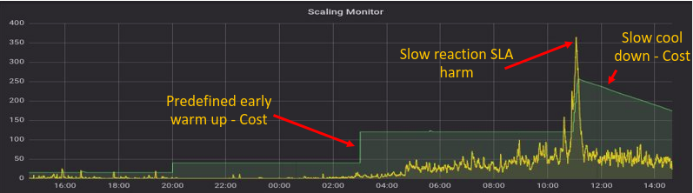
Como indica el gráfico, depender de métricas predeterminadas para monitorear la utilización de la capacidad cada 5 minutos resulta en la incurrencia de costos por máquinas que no están en uso, además de perjudicar los niveles de servicio al operar con máquinas inadecuadas (por ejemplo, entre las 10:00 y las 12:00 en el gráfico).
Ir más allá de la profundidad de cola como métrica de escalado
La profundidad de cola ha sido y seguirá siendo un factor influyente clave en las decisiones de escalado dentro de los sistemas basados en eventos. Sin embargo, depender únicamente de la profundidad de cola como métrica de escalado genera un enfoque reactivo para la optimización de la infraestructura.
Cuando hay un mensaje esperando en una cola, consume un tiempo de cómputo valioso que preferiríamos dedicar a un mensaje que está siendo procesado por un servicio. Por lo tanto, es ideal disponer de cierta capacidad de cómputo de reserva en todo momento. Estos sistemas de reserva esperan la llegada de nuevos mensajes a la cola para poder procesarlos de inmediato sin demoras. Naturalmente, este enfoque proactivo es superior a tener que añadir máquinas cuando los mensajes ya están en la cola y reducir la escala cuando la cola ya está vacía. La necesidad de capacidad de reserva revela una perspectiva importante: la profundidad de la cola no cuenta toda la historia.
Por lo tanto, la ecuación correcta para el escalado debería ser, de hecho:
Demanda = Mensajes en cola + mensajes en proceso + máquinas de reserva
La necesidad de una medición más frecuente de la capacidad y la carga
Como hemos establecido en las secciones anteriores, depender de métricas de escalado solo una vez cada 5 minutos no solo es costoso, sino que también perjudica los niveles de servicio y la satisfacción del cliente. Para superar esto, desarrollamos un servicio que mide la profundidad de la cola y los mensajes en proceso cada segundo a través de una API. Al comparar el antiguo método de muestreo con el nuevo, las mejoras fueron muy evidentes. En la ilustración a continuación, la demanda (línea amarilla) nunca excede la oferta (línea verde).
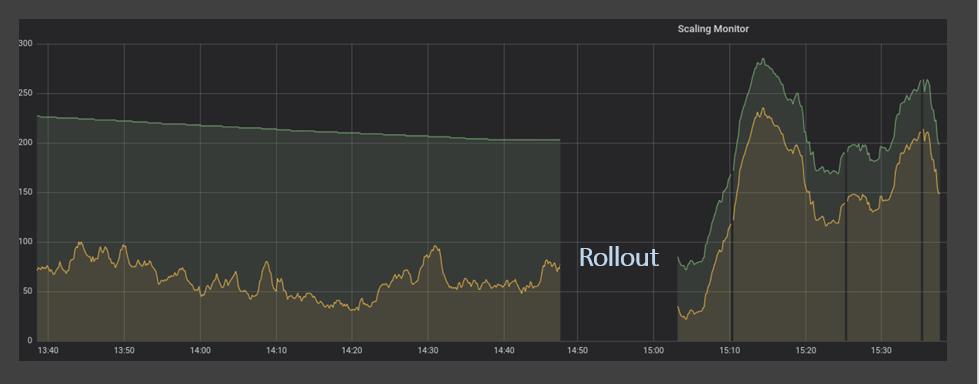
Observe que, cuando la demanda aumenta bruscamente, la oferta reacciona muy rápidamente, protegiendo eficazmente a nuestros clientes de retrasos desagradables en el servicio.
Además, este método ayuda a mantener nuestra capacidad de cómputo de reserva estrechamente alineada con la demanda, en lugar de gastarla en instancias inactivas que esperan nuevos mensajes.
Ajuste de escala con precaución
Un escalado agresivo realizado incorrectamente conlleva un peligro claro e inminente: la posibilidad de desescalar máquinas que aún están procesando información. En la fábrica de Trax, por ejemplo, los algoritmos basados en geometría suelen requerir más tiempo de procesamiento en comparación con otros servicios. Retirar la capacidad de cómputo de este servicio demasiado pronto resulta en que el mensaje sea devuelto a la cola. Como consecuencia, además de indicar el flujo natural de entrada al sistema, los informes de demanda incluyen mensajes que regresan a la cola por segunda vez, y quizás por tercera o cuarta vez. Esta carga puede aumentar drásticamente con el tiempo e impactar tanto en los costos como en los niveles de servicio.
Para evitar que esto suceda, implementamos un mecanismo mediante el cual los servicios que levantan una bandera indicando que aún están procesando mensajes son 'excluidos'. Esto evita que dichas instancias sean objeto de decisiones de escalado. La mayoría de los proveedores de la nube ofrecen funcionalidades que 'protegen' las instancias de forma selectiva. Una vez que el servicio completa el procesamiento del mensaje, retira la bandera y regresa al grupo de recursos de cómputo que participan en el proceso de escalado. Esta capacidad asegura que solo las máquinas inactivas sean desescaladas.

En el gráfico anterior, observamos la demanda y la oferta en armonía. Pero observe algo que no habíamos visto antes. Hay una nueva línea roja que siempre se mantiene cerca del eje X. Esta línea representa el retraso en nuestro sistema. En efecto, este es el tiempo durante el cual el mensaje más antiguo permanece en la cola antes de ser procesado. El hecho de que las líneas de oferta y demanda funcionen como deberían, combinado con que el retraso sea cercano a cero la mayor parte del tiempo, significa que los niveles de servicio no se ven afectados.
Contingencia robusta
Como dice Werner Vogels, CTO de Amazon, «todo falla todo el tiempo». Hemos introducido un cambio tecnológico importante y desarrollado un servicio que mide la profundidad de la cola y los mensajes en proceso, y realiza una operación de escalado en nuestro sistema. La falla de este servicio significa, en efecto, que perderemos toda la capacidad de escalado, la materia de la que están hechas las pesadillas de los CTO. Para evitar esto, se ha implementado un plan de recuperación ante desastres. El mecanismo original de consulta de la profundidad de la cola cada 5 minutos sigue vigente y los dos sistemas funcionan en paralelo. De esta manera, si uno de ellos falla, los niveles de servicio no se ven gravemente afectados.
Los puntos clave
Aquí se presenta una representación de nuestra solución completamente funcional operando en un día típico a mitad de semana:
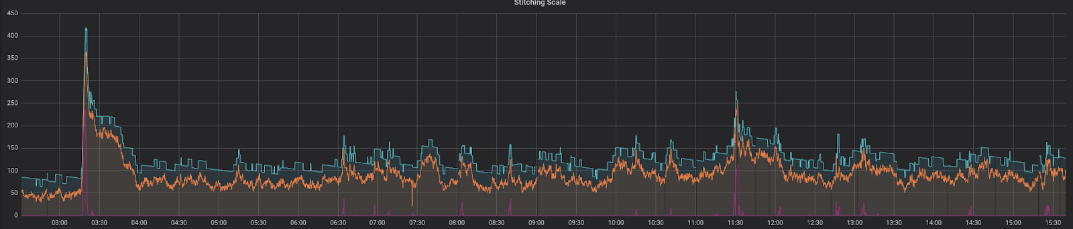
Esto muestra una correlación perfecta entre las máquinas esperadas (línea naranja) y las máquinas reales (línea azul), con una cantidad suficiente de capacidad de cómputo de reserva. El tiempo durante el cual el mensaje más antiguo permanece en la cola antes de ser procesado (línea roja) es consistentemente bajo, con picos solo durante períodos muy cortos.
En resumen, la construcción de un mecanismo de escalado para sistemas asíncronos basados en eventos que Trax ha desarrollado se basa en cuatro pilares fundamentales:
El éxito se define por el grado de satisfacción de los responsables de la gobernanza del escalado —el CFO, COO y CTO— con la solución. El resultado de esta innovación beneficia a todos:
Michael Feinstein también impartió una sesión sobre este tema en Reversim 2018. Haga clic en el botón de reproducción para ver la sesión completa.










